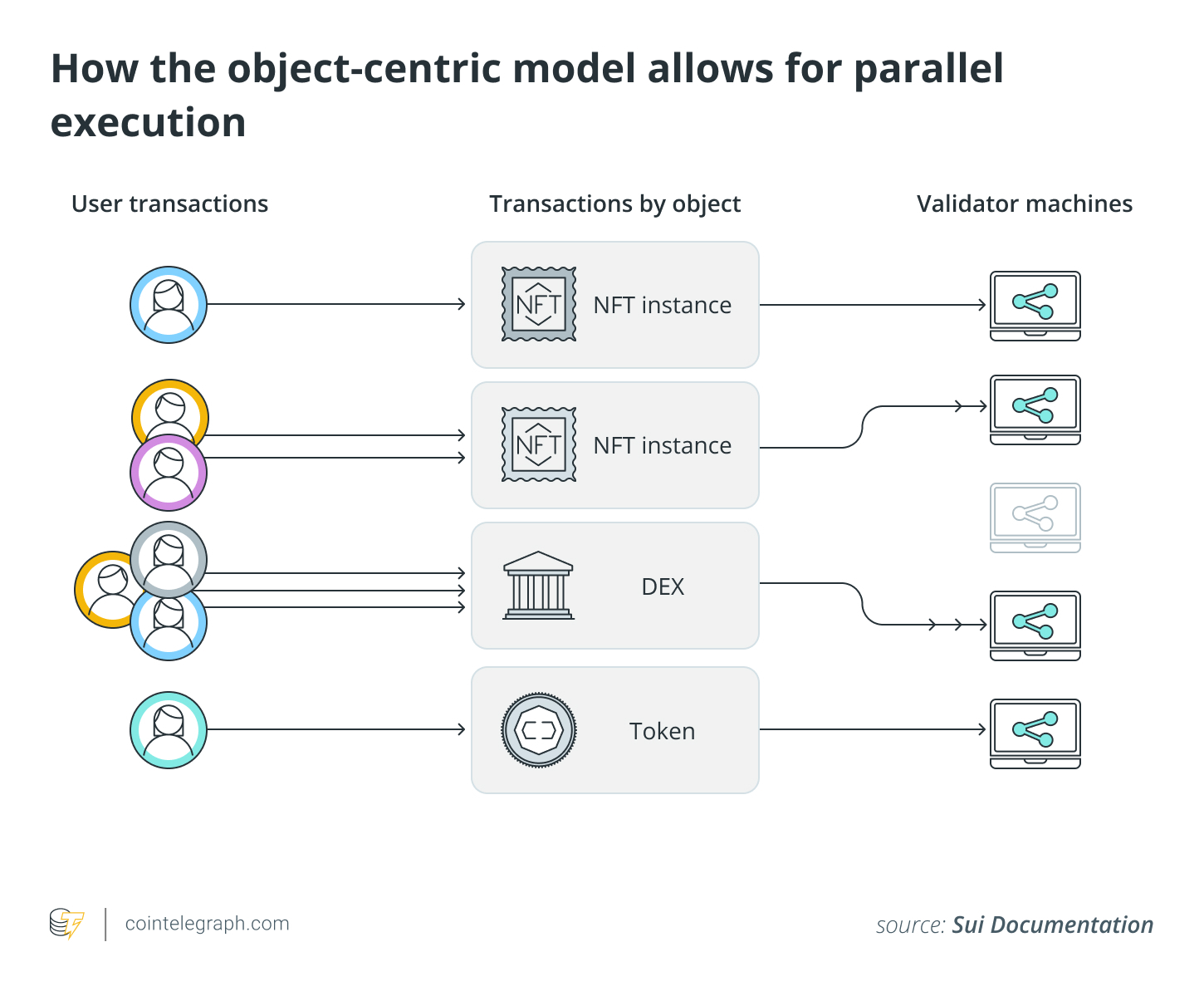
What is object-centric representation?
Object-centric representation learning decomposes visual input into discrete, independent entities rather than treating it as a flat grid of pixels. Each entity is captured in a "slot" or "object file" that encodes properties like position, color, and identity. This structure enables systems to reason about individual objects and their interactions, leading to better causal understanding and data efficiency.
Think of it like organizing a messy desk. Instead of seeing a single pile of chaos, you identify individual items—a pen, a notebook, a coffee cup—and understand their separate roles. This disentanglement is crucial for efficiency. Research shows that object-centric architectures can leverage weak supervision from sparse perturbations to isolate each object's properties, making the model more robust and interpretable.
This shift enables better causal representation, meaning the system understands how changes to one object affect others without relearning the entire scene. It moves beyond pattern matching toward genuine structural understanding.
Object-centric architecture choices that change the plan
Use this section to make the The Rise of Object-Centric Architecture decision easier to compare in real life, not just on paper. Start with the reader's actual constraint, then separate must-have requirements from details that are merely nice to have. A practical choice should survive normal use, maintenance, timing, and budget. If a recommendation only works in an ideal situation, call that out plainly and give the reader a fallback path.
Choose the Next Step: Turn Research into a Decision Framework
Object-centric architectures excel when labeled data is scarce. If your dataset relies on sparse perturbations or weak supervision, this approach reduces the need for exhaustive pixel-level annotations. Evaluate whether your current labeling pipeline can support the fine-grained supervision required for disentangled representations. If annotation costs are prohibitive, object-centric models offer a more efficient alternative to dense supervised learning.
Disentangling objects in real-time demands significant computational overhead. If your application requires low-latency inference, such as autonomous navigation or real-time video analysis, test whether your hardware can handle the iterative slot refinement processes. Compare the inference speed of object-centric models against standard CNNs on your specific hardware. If throughput is critical, consider distilling the object-centric model into a lighter, non-disentangled architecture.
A primary advantage of object-centric representation is interpretability. Each slot corresponds to a specific object, making it easier to debug model errors or explain decisions to stakeholders. If your domain, such as healthcare or finance, requires transparent decision-making, this architecture provides inherent explainability. Assess whether your team can leverage these distinct object files for auditing or user-facing explanations.
Object-centric models struggle with highly dynamic scenes where objects frequently occlude or merge. If your use case involves crowded environments or rapidly changing contexts, test the model's ability to maintain slot integrity. Consider hybrid approaches that combine object-centric slots with global scene descriptors. If the model fails to disentangle objects under high occlusion, you may need to adjust the inductive biases or introduce additional regularization.
Watch Out for Misleading Claims and Weak Options
Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files," where each slot captures a distinct object. While this approach promises efficient causal representation, several implementations fail to deliver on that promise. The primary risk lies in confusing simple attention mechanisms with true object-centric disentanglement.
Many modern architectures claim object-centric capabilities but rely on soft attention that blends features rather than isolating them. This creates a false sense of modularity. Without weak supervision from sparse perturbations, the model cannot reliably disentangle each object's properties. The result is a system that appears structured but lacks the causal independence required for robust reasoning.
Another common mistake is over-relying on synthetic data. While synthetic datasets make training easier, they often lack the noise and complexity of real-world scenes. Models trained exclusively on clean, generated data struggle when deployed in production environments. Always verify that the architecture has been tested against real-world perturbations.
Finally, be wary of solutions that prioritize speed over interpretability. Object-centric architectures are valuable because they offer clear, human-readable representations. If a system sacrifices this clarity for marginal performance gains, it defeats the core purpose of the architecture.
Object-centric architecture: what to check next
Before committing to an object-centric architecture for 2026 digital ecosystems, it helps to understand what the model actually does and where it fits. This approach decomposes complex scenes into modular, object-level representations. Instead of treating an image as a single blob of pixels, the system identifies distinct entities—like a person, a car, or a tree—and tracks them individually. This separation allows for clearer causal reasoning and more efficient data storage.
The shift toward object-centric design is driven by the need for systems that can reason about the world like humans do. We don't see a "crowd"; we see individuals. By mirroring this, 2026 architectures promise more robust, interpretable, and scalable digital environments.
No comments yet. Be the first to share your thoughts!