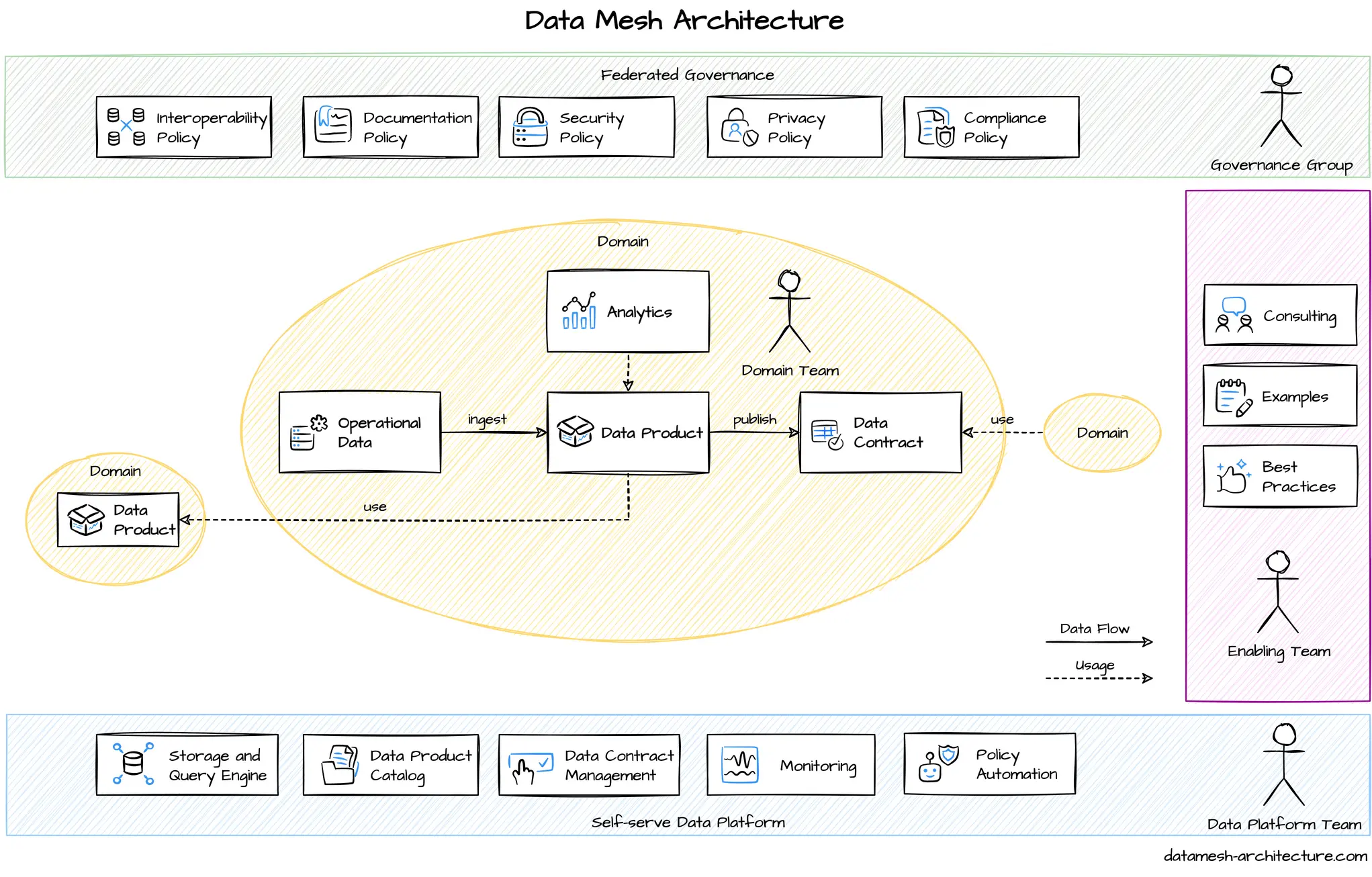
What object-centric architecture means
Object-centric architecture shifts the fundamental unit of data modeling from flat tables or monolithic services to distinct, interacting entities. Instead of forcing information into rigid rows and columns, this approach treats each entity—like a customer, a product, or a transaction—as a self-contained object with its own state and boundaries. This structural change mirrors how data naturally exists in the real world, where things interact rather than just sit in isolated lists.
In traditional relational models, data is often normalized to avoid redundancy, which can scatter related information across dozens of tables. Object-centric architecture keeps related attributes and behaviors together. For example, an Order object doesn't just hold an ID and a timestamp; it encapsulates the items purchased, the shipping address, and the payment status as internal properties. This reduces the cognitive load required to understand how different parts of the system relate to one another.
This model also facilitates better causal representation. By disentangling each object's properties, systems can more easily track how changes in one entity affect others without triggering cascading updates across a fragile web of foreign keys. It creates a clearer, more maintainable structure for complex data ecosystems, laying the groundwork for the decentralized autonomy required in modern data mesh implementations.

Why data mesh needs object models
Traditional data mesh implementations often default to flat, siloed tables. This approach treats data as a collection of disjointed records rather than a coherent domain. When teams own tables instead of business entities, interoperability breaks down. One team might define "Customer" as a list of transactions, while another defines it as a profile with preferences. The result is a fragmented landscape where joining data requires constant reconciliation.
Object-centric models resolve this by aligning data structures with domain boundaries. Instead of managing isolated rows, teams define objects that encapsulate state and behavior. This mirrors how software architecture handles complexity: by bundling related data into meaningful units. An object model ensures that a "Product" always carries its price, inventory, and metadata together, reducing the cognitive load for consumers.
The visual difference is stark. A table-based mesh looks like a tangled web of service dependencies, requiring complex joins to reconstruct a single entity. An object-centric mesh resembles a clean graph of interconnected domain objects. Each node represents a complete business concept, linked clearly to others. This structure supports true domain ownership because the owning team controls the object's lifecycle, not just its storage.
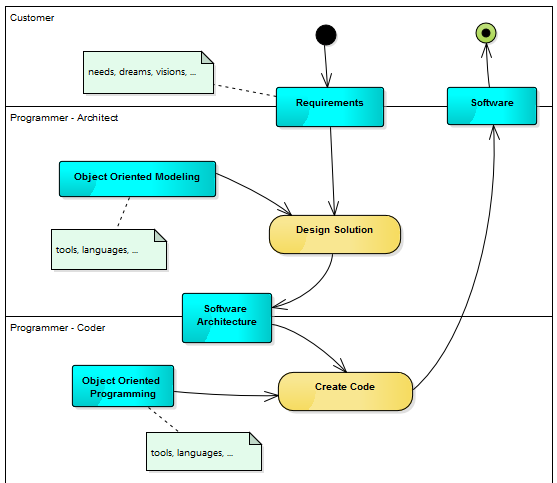
Designing Domain-Driven Object Models
In a data mesh, an object is not a database row waiting to be queried; it is a self-contained unit of business logic. When designing these models, the focus shifts from schema normalization to encapsulation. You are building digital twins of domain concepts—like Order, Customer, or InventorySlot—that carry their own behavior and state.
Consider the difference between a traditional table and a domain object. A table stores order_id, customer_id, and status as isolated columns. A domain object, however, knows how to transition from pending to shipped only if specific business rules are met. This behavior lives inside the object, ensuring that data integrity is enforced by the object itself, not by external scripts or database triggers.
This approach mirrors how we perceive the physical world. Just as a Car object knows how to accelerate or brake rather than just storing speed values, your data models should reflect the actions and rules of your business domain. This makes the code more intuitive and reduces the cognitive load on developers who interact with the data.
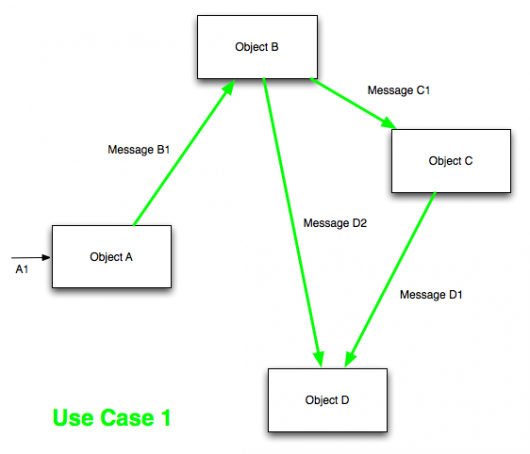
The visual representation of these objects should highlight their interactions. Instead of a sprawling ER diagram with foreign keys, use sequence diagrams or class diagrams that show how objects send messages to one another. This clarity helps teams understand the boundaries of their domains and prevents the "anemic domain model" anti-pattern, where objects are little more than data containers.
Key Principles for Robust Object Models
-
Encapsulation First
Keep data and the methods that operate on that data within the same object. This prevents external code from creating inconsistent states. -
Behavior Over Data
Define what an object can do (e.g., applyDiscount) rather than just what it is. Behavior drives the structure of your model. -
Immutable by Default
Prefer immutable objects where possible. This simplifies reasoning about state changes and reduces side effects in concurrent environments. -
Clear Boundaries
Use domain events to communicate between objects. This decouples components and allows for easier scaling and testing.
Implementing object-centric pipelines
Building an object-centric architecture requires shifting from flat, relational tables to a stateful, versioned model where each entity is a first-class citizen. This approach treats data not as a collection of rows, but as a set of interacting objects with their own lifecycle, history, and serialization rules.
1. Define the object model
Start by identifying the core entities in your domain—such as User, Order, or SensorReading. Unlike traditional schemas where these are normalized across tables, object-centric models encapsulate all relevant attributes within a single object definition. This reduces join complexity and aligns the data structure with the business logic it represents.
2. Implement state management
Objects in a distributed environment must track their state transitions. Instead of updating rows in place, append state changes as immutable events. This ensures that every modification is traceable and allows the system to reconstruct any point in time. For example, an Order object might transition from created to shipped to delivered, with each state change recorded as a distinct event.
3. Version and serialize objects
To support efficient causal representation, serialize objects using a format that preserves structure and metadata, such as Protocol Buffers or JSON Schema. Versioning is critical; each object should carry a version number to handle schema evolution. This allows different parts of the system to consume different versions of the same object without breaking compatibility, enabling smoother upgrades and rollbacks.
4. Handle distributed consistency
In a mesh architecture, objects are often accessed across services. Use optimistic concurrency control to manage updates, ensuring that conflicts are detected and resolved at the object level. This prevents race conditions and maintains data integrity without requiring heavy locking mechanisms. The goal is to make each object self-contained and independently manageable.
5. Test with perturbations
Validate your architecture by introducing sparse perturbations to object properties. This technique, known as weak supervision, helps disentangle object properties and ensures that the system can handle unexpected changes gracefully. By testing how objects react to minor data shifts, you can verify that the causal relationships between properties are correctly modeled and robust.
Identify core entities and encapsulate attributes within a single definition to reduce join complexity.
Append state changes as immutable events to ensure every modification is traceable.
Use structured formats like Protocol Buffers and version numbers to handle schema evolution.
Use optimistic concurrency control to manage updates and prevent race conditions.

Validate the system by introducing sparse perturbations to ensure robust causal relationships.
Common pitfalls in object modeling
Even with a solid data mesh strategy, object modeling often collapses under its own weight. The most frequent error is over-engineering hierarchies, creating deep inheritance trees that look elegant in a diagram but become unmanageable in production. When every entity requires a specialized subclass, the system becomes brittle; a minor change in one branch can cascade through unrelated services, breaking contracts and increasing maintenance costs.
Another critical trap is ignoring the performance cost of serialization. In high-throughput environments, deeply nested objects force the system to traverse and serialize large graphs even when only a small subset of data is needed. This overhead can turn simple read operations into latency bottlenecks, negating the efficiency gains of a decoupled architecture.
To avoid these traps, keep your object models flat and focused on the specific data required by the consumer. Prioritize composition over inheritance, and explicitly define the boundaries of each object to prevent unnecessary coupling. This approach ensures your data mesh remains scalable, performant, and easy to maintain as your system grows.
Future trends for object-centric data
Object-centric architecture is moving from a computer vision novelty to a core requirement for reliable AI systems. The goal is no longer just to detect a car or a person in an image, but to build a model that understands those entities as independent agents with their own physics and intentions. This shift enables causal representation learning, where AI can reason about "what if" scenarios rather than just pattern matching.
Recent research highlights how weak supervision can disentangle object properties. For example, a system might learn to separate a car’s color from its motion vector by observing sparse perturbations in the environment. This allows the model to generalize better when conditions change, such as moving from a sunny dataset to a rainy one, without retraining from scratch.
The visual representation of these objects becomes a structured graph rather than a flat pixel array. Each node in the graph represents an entity, and the edges represent their interactions. This structure allows AI to predict outcomes more accurately, similar to how humans intuitively understand that a ball will bounce off a wall.
As these models mature, they will power more robust autonomous systems and personalized assistants. By treating data as a collection of interacting objects, we move closer to AI that understands the world in a way that mirrors human cognition.
No comments yet. Be the first to share your thoughts!